Nifty__
Nifty__

Deixis was a human-robot interaction study, which incorporated human trials to investigate the perception of robotic deictic gestures. A “deictic gesture” is a form of nonverbal communication that typically serves to focus an observer’s attention to a specific object or location in the environment. Humans will often employ nonverbal modalities such as facial expression, eye gaze, head orientation, and arm gesture to signal intent “here” or “there”. For example, when dining at a foreign restaurant, I will extend my index finger toward a menu item to signal my intent to order “this” cheeseburger.
Similarly, when humans and robots are involved in a collaborative task in a shared environment, robots must utilize deictic gestures to sustain effective communication and natural interaction; robots cannot always rely on speech to communicate. The Deixis Project is an experimental study of the human perception of a humanoid robot’s deictic gestures under a set of different environmental conditions and pointing modalities. It attempts to gain an empirical understanding of how to map well-studied human gestures to robots of varying capabilities and embodiments.
This project was developed in the summer of 2010 during an NSF research fellowship under the direction of Ph.D candidates, Aaron St. Clair and Ross Mead, and Dr. Maja Matarić.
The Deixis project utilized “Bandit” as the gesturing robot, the SICK LMS for finding markers, overhead and forward-facing cameras for head-tracking, and a Wiimote for facilitating the experiment.
This project was software-intensive, requiring the integration of several sub-projects for deictic gesture validation and a user-studies experiment. It heavily utilized C++ and the Robot Operating System (ROS) framework for controlling Bandit’s movements, collecting data, and manipulating data output.
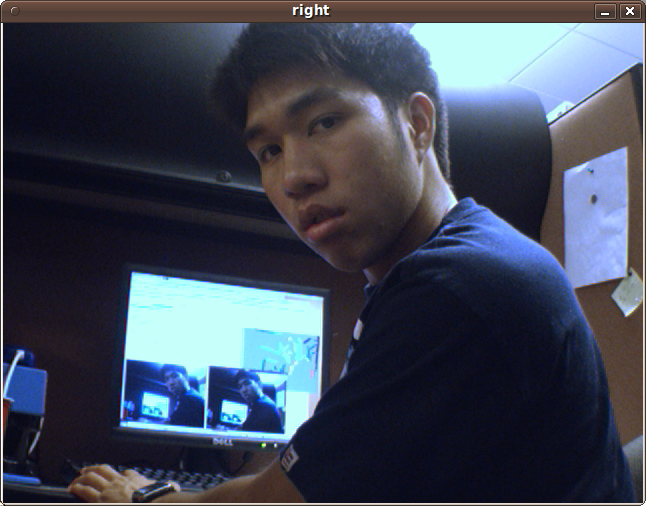
The Bandit robot has cameras situated in its left and right eyes. This stereo camera setup simulates human binocular vision to perceive depth, thus being able to capture three-dimensional images. When the cameras are calibrated, 3D information can be extracted by examination of the relative positions of objects in the left and right images.
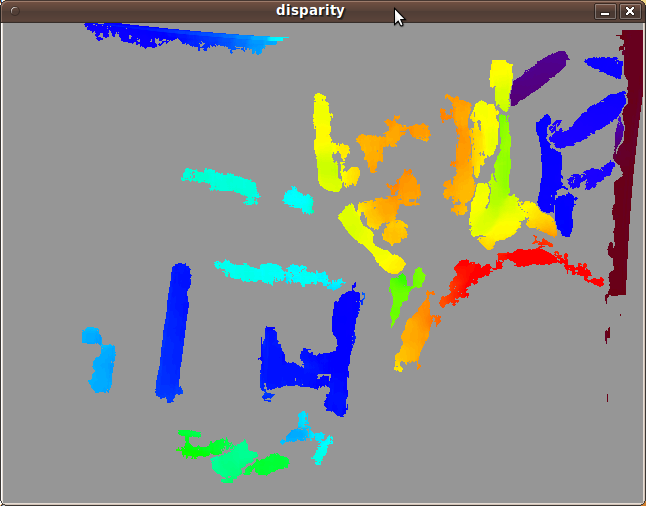
The cameras must be calibrated properly to relieve the images of distortions. This is performed using ROS’ checkerboard camera calibration technique. The raw stereo camera image pairs can then be rectified and de-mosaic’d to generate dispaity maps and point clouds (stereo_image_proc).
Here is an example of me sitting at my desk. Raw camera images are collected from the left and right cameras to generate a disparity map and a point cloud, which can be viewed in RViz to display depth information.

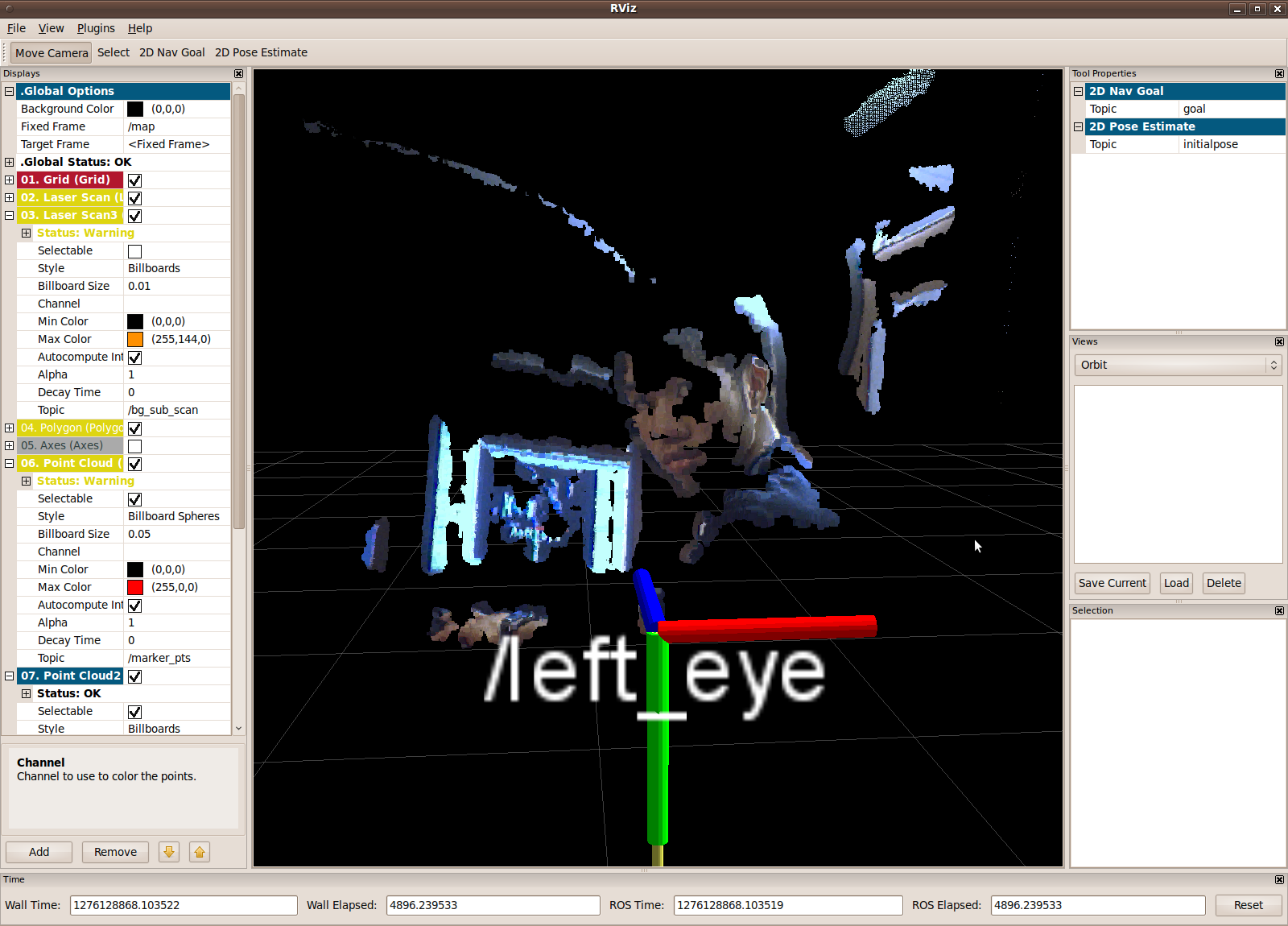
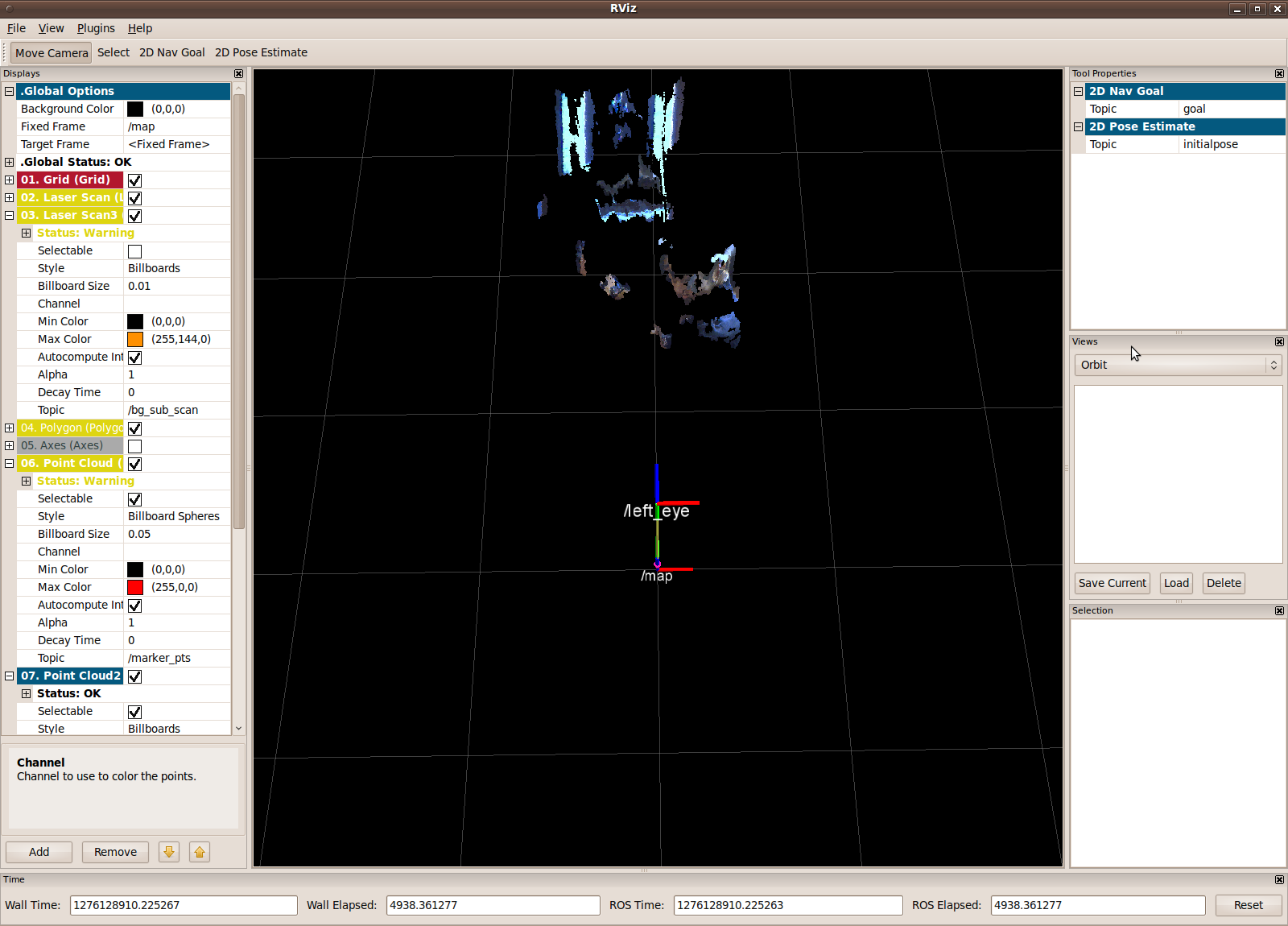
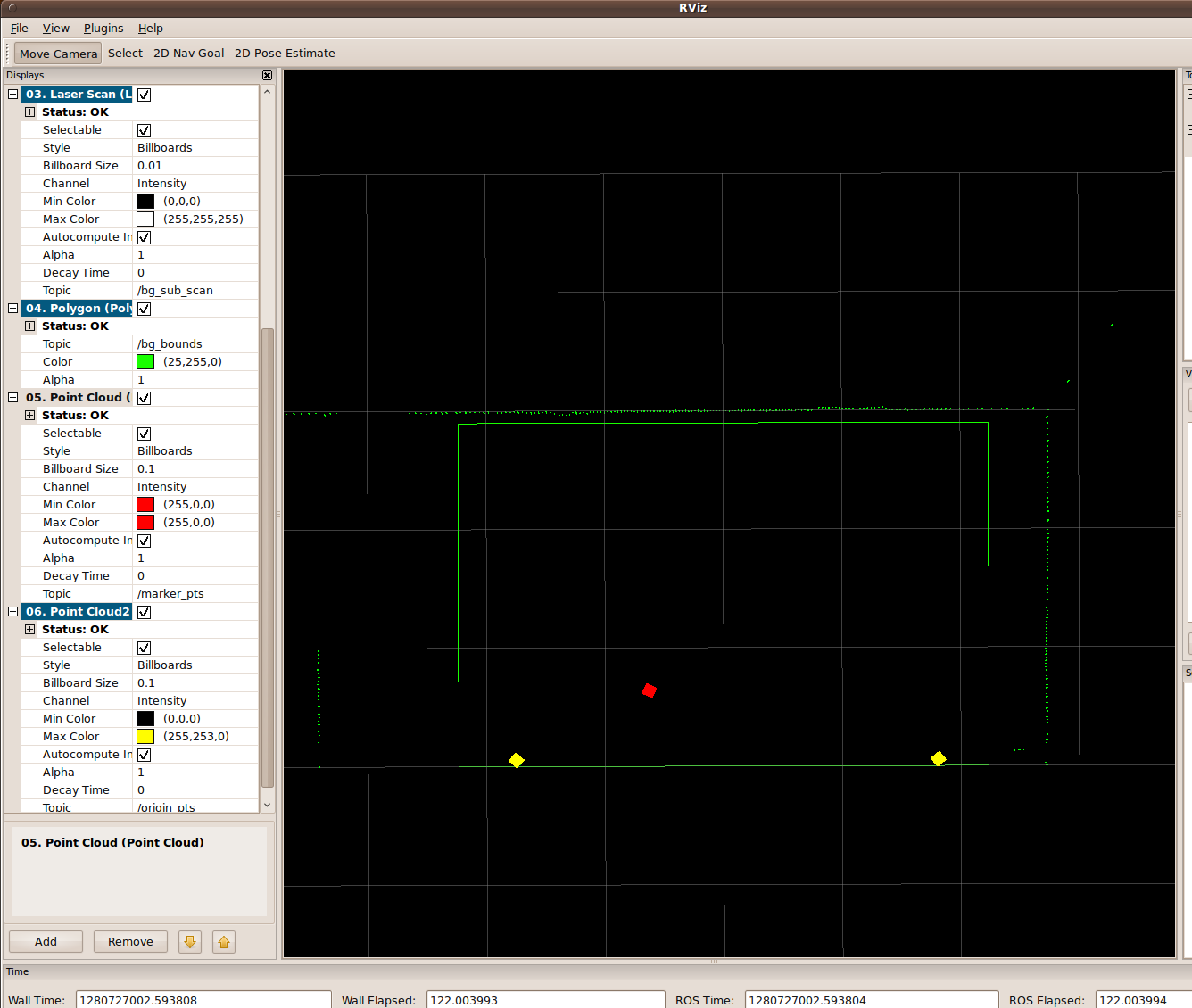
The marker_finder is a program used to log a human’s perception of robot gestures. It utilizes the SICK laser measurement sensor to capture the exact position on a screen where a human believes the robot is pointing. The SICK LMS is oriented facing upwards so that it can capture the proximity of objects sticking out from the screen, scanning 180-degrees from the floor.
In the image below, the rectangular outline represents the screen. The two symmetric yellow square points represent the screen’s standoff legs, which hold the screen in place. For the experiment, I used a Pringles can to serve as the “marker”, which is detected in the generated point cloud as a cluster of points. The absolute position of the marker is logged and represented by the red square point.
Head orientation was captured using a head-mounted ARTag. The ARTag’s square physical markers are tracked in real time, allowing the calculation of camera position and orientation relative to the marker.
A “bag” is a ROS file format for storing ROS message data. In the Deixis experiment, several ROS topics are published including image data from cameras, point clouds, joystick button presses, and robot joint angles. All of this data can be recorded and played back using a tool like rosbag.
The bag2video package is a utility that will consume a bag file of compressed images, and return a .avi file of variable framerate (hence the name, “bag2video”). It uses image_transport for publishing/subscribing to images between ROS nodes, and CvBridge to convert between ROS image messages and OpenCV IPLimages. The videos I converted use ARTags, which are used for tracking head orientation through augmented reality.
A Wiimote controller was used to facilitate the experiment and save waypoint coordinates with sensor input from the SICK LMS. The program used the ROS wiimote package to communicate over a Bluetooth connection, returning button, LED, rumble, and accelerometer/gyro data on the /joy ROS node.

The Deixis experiment was designed to observe the effects of visual saliency and pointing modality on a human’s perceptual accuracy of robotic deictic gestures. In the experiments, the participant is seated facing Bandit at a distance of 6 feet. The robot and the participant are separated by a transparent, acrylic screen measuring 12ft x 8ft. The robot then performs a series of deictic gestures and the participant is asked to estimate their referent location on the screen.
Participants were given a laser pointer to mark their estimated location for each gesture. These locations were recorded using a laser rangefinder placed facing upwards at the base of the screen. For each gesture, an experimenter placed a fiducial marker over the indicated location, which was subsequently localized within approximately 1cm using the rangefinder data. The entire experiment was controlled via a single Nintendo Wiimote, with which the experimenter could record marked locations and advance the robot to point to the next referent target.
Bandit gestured to locations on the transparent screen using different pointing modalities such as moving its head (2 DOF), arm (7 DOF), or both together. The robot is posed using a closedform inverse kinematic solution; however, a small firmware “dead-band” in each joint sometimes introduces error in reaching a desired pose. To monitor where the robot actually pointed, we computed forward kinematics using angles from encoder feedback, which we verified were accurate in a separate controlled testing. All gestures were static and held indefinitely until the participant estimated a location, after which the robot returned to a home location (looking straight forward with its hands at its sides) before performing the next gesture. This was intended to minimize any possible timing effects by giving participants as long as they needed to estimate a given gesture.

In cluttered environments containing many visually salient targets, it can be challenging for observers to decipher between objects. The Deixis experiment tested two saliency conditions: a blank (or non-salient) environment and an environment with several highly and equally visually salient targets. It was expected that salient objects would affect people’s interpretations of the points. Specifically, that participants would “snap to” the salient objects, thus reducing error for points whose targets were on or near markers, whereas in the non-salient condition there were no points of reference to bias estimates.
Experiments were conducted in two phases, reflecting the two saliency conditions. In the salient condition, the robot’s gestures included 60 points toward salient targets and 60 points chosen to be on the screen, but not necessarily at a salient target. In the non-salient condition, 74 of the points within the bounds of the screen were chosen pseudo-randomly and the remaining 36 were chosen to sample a set of 4 calibration locations with each pointing modality.
My work with the Deixis project contributed to this publication, which contains a statistical data analysis of the experiments.
. “Investigating the Effects of Visual Saliency on Deictic Gesture Production by a Humanoid Robot”. In IEEE 20th IEEE International Symposium in Robot and Human Interactive Communication (Ro-Man 2011), Atlanta, GA, Jul 2011
Additional detail can be found at robotics.usc.edu/~hieu.
